The IONOS AI Model Hub is the IONOS service for cloud-hosted LLMs. It is an easy-to-use service that exposes Large Language Models through OpenAI API compatible endpoints. At the time of writing, 8 language models are available, 2 text-to-image models and 3 embedding models.
Available models at IONOS AI Model Hub
| Model | Description |
| Llama 3.1 8B Instruct language model | Llama 3.1 (8B parameters version) is an auto-regressive language model that uses an optimized transformer architecture. It was released by Meta AI on July 23, 2024, and utilizes supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety. The knowledge cutoff for this model is December 31, 2023. |
| Teuken-7B Instruct language model | Teuken-7B Instruct is a 7-billion parameter instruction-tuned language model designed for conversational and instruction-following tasks. Fine-tuned to better understand and respond to natural language prompts, it aims to provide clear, coherent, and helpful outputs in dialogue and question-answering scenarios. Its open-source nature makes it accessible for research and application in various natural language processing projects. |
| Mistral Nemo Instruct language model | Mistral Nemo Instruct is an instruction-tuned large language model developed by Mistral AI. Tailored for following natural language instructions, it is optimized for conversational tasks, question answering, and providing helpful, safe responses. Mistral Nemo Instruct combines efficiency with strong reasoning and communication abilities, making it suitable for chatbots, virtual assistants, and various natural language understanding applications. |
| Code Llama 13b Instruct HF language model | Code Llama 13B Instruct HF is an open-source large language model developed by Meta, featuring 13 billion parameters. Fine-tuned in an “instruct” setting, it is optimized to follow natural language commands, assist with programming tasks, and generate code across multiple programming languages. The “HF” denotes its availability in Hugging Face format, enabling easy integration with popular machine learning libraries for research and development. |
| Mistral Small 24B Instruct language model | Mistral Small 24B Instruct is a large language model (LLM) developed by Mistral AI. It features 24 billion parameters and is specifically fine-tuned for high-quality instruction following and chat applications. Renowned for its strong reasoning abilities, coding competence, and safe, helpful dialogue, Mistral Small 24B Instruct offers an optimal balance between performance and efficiency for a wide range of conversational AI tasks. |
| gpt-oss-120b language model | gpt-oss-120b is a large open-source language model featuring 120 billion parameters. It is designed to provide advanced natural language understanding and generation capabilities for a variety of tasks, such as text synthesis, question-answering, and dialogue. The model aims to deliver performance comparable to leading proprietary LLMs and serves as a resource for research and development in the open-source AI community. |
| Llama 3.3 70B Instruct language model | Llama 3.3 is an instruction-tuned generative language model optimized for multilingual dialogue use cases. It was released by Meta AI on December 6, 2024, and utilizes an advanced transformer architecture and is designed to align with human preferences for helpfulness and safety through supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF). The knowledge cutoff for this 70B model is December 31, 2023. |
| Llama 3.1 405B Instruct language model | Llama 3.1 405B Instruct is a cutting-edge large language model from Meta AI, featuring an impressive 405 billion parameters. Fine-tuned with an instruction-following objective (“Instruct”), it excels in understanding and responding to complex prompts across diverse topics. Llama 3.1 405B Instruct offers state-of-the-art language generation, reasoning, coding support, and conversational abilities, making it highly effective for advanced AI applications in research, industry, and development. |
| Stable Diffusion XL text-to-image | Stable Diffusion XL (SDXL) is an advanced text-to-image generative model developed by Stability AI. Building on earlier versions of Stable Diffusion, SDXL produces high-quality, detailed, and photorealistic images from natural language prompts. It supports longer, more complex prompts and offers improved composition, color fidelity, and image resolution compared to previous models. SDXL is widely used for creative projects, concept art, and visual design tasks, and is available as an open-source model for both research and commercial applications. |
| FLUX.1 [schnell] text-to-image | FLUX.1 [schnell] is an open-source 12-billion-parameter Rectified-Flow Transformer from Black Forest Labs, optimized for its speed and efficiency in text-to-image generation. By using latent adversarial diffusion distillation, the model delivers high-quality images in just 1 to 4 steps, often with sub-second results. This focus on speed makes it the ideal tool for rapid iteration, prototyping, and personal projects, consciously making a trade-off in favor of speed over maximum detail. |
| paraphrase-multilingual-mpnet-base-v2 embedding | paraphrase-multilingual-mpnet-base-v2 is a sentence embedding model developed by SentenceTransformers. Based on the MPNet architecture, it is trained to produce high-quality vector representations for sentences in multiple languages. The model excels at semantic textual similarity, paraphrase mining, and multilingual search tasks, making it valuable for applications in cross-lingual information retrieval, clustering, and natural language understanding. |
| bge-large-en-v1.5 embedding | bge-large-en-v1.5 is a large English sentence-embedding model (version 1.5) that produces high-quality vector representations of text. It is optimized for semantic search, clustering, paraphrase detection, and retrieval tasks, offering improved accuracy and discrimination compared with smaller variants. Common uses include building semantic search engines, similarity ranking, and downstream classification or clustering workflows. |
| bge-m3 embedding | bge-m3 is a multilingual text-embedding model in the BGE family that produces high-quality vector representations for sentences and documents across many languages. It is optimized for semantic search, cross-lingual retrieval, clustering, and similarity tasks, offering robust performance and discrimination across diverse domains. Common uses include building multilingual semantic search engines, reranking, paraphrase detection, and downstream classification or clustering workflows. |
AI Model Hub Pricing
The IONOS AI Model Hub usage is charged per million tokens. Taking the popular models Llama 3.3 70B Instruct and gpt-oss-120b as a benchmark, the IONOS AI Model Hub pricing is competitive.
| Provider | Llama 3.3 70B Instruct Price | gpt-oss-120b Price |
| € 0,65 input / € 0,65 output | € 0,15 input / € 0,65 output | |
| € 0,45 input / € 0,65 output | € 0,45 input / € 0,65 output | |
| € 0,90 input / € 0,90 output | € 0,15 input / € 0,60 output | |
| € 0,79 input / € 0,79 output | – |
IONOS AI Model Hub: First Steps
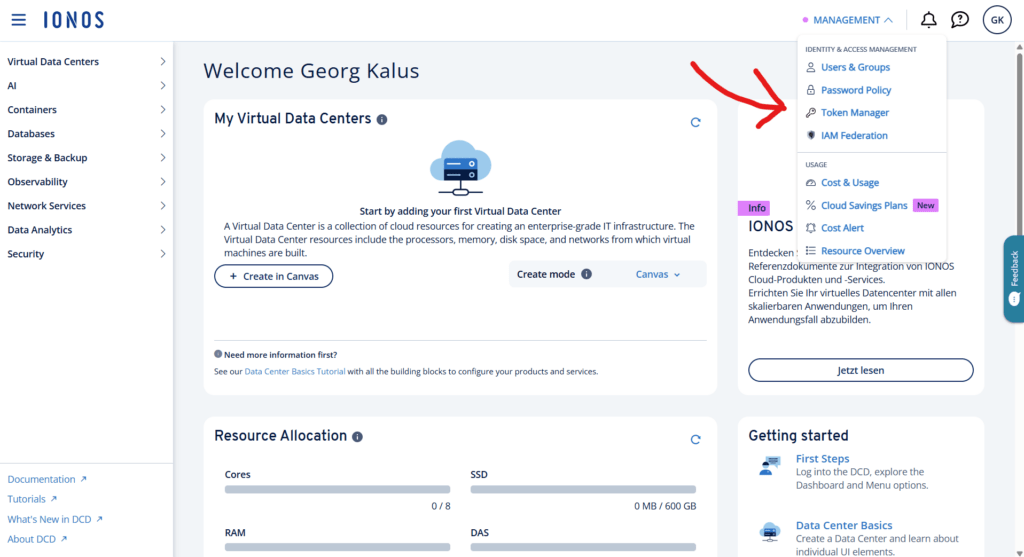
AI models in the IONOS AI Model Hub are exposed as an OpenAI compatible API. Usage of IONOS-hosted models is therefore as simple as with any other provider. All we need is an Authentication Token, which can be obtained in the IONOS Data Center Designer. The Token Manager can be found in the Management menu in the DCD.
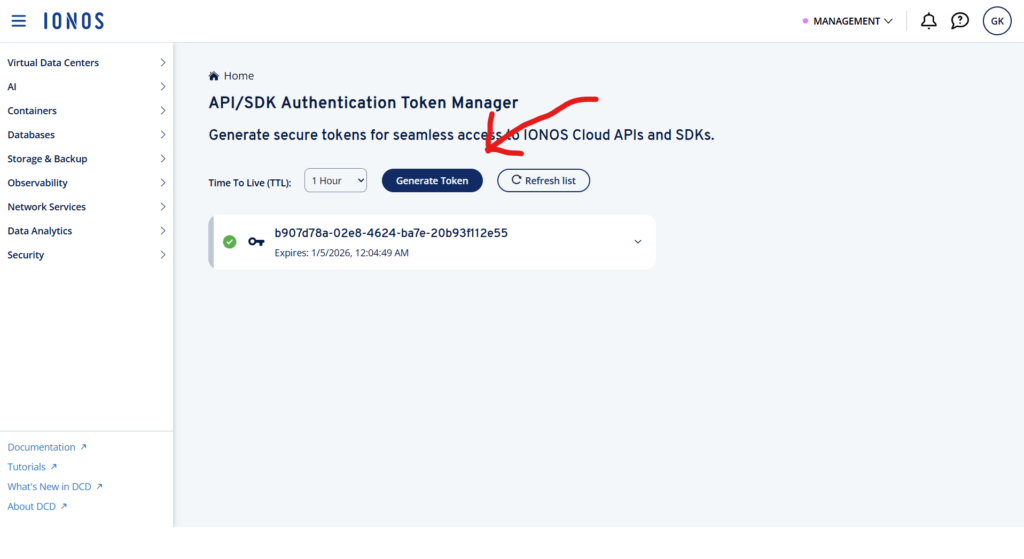
In the Token Manager, chose how long the token should be valid in the Time To Live drop down and then click Generate Token and copy the secret value that is shown.
There are some great use case examples and How-Tos in the AI Model Hub documentation.
Resources
- IONOS AI Model Hub product website
- IONOS AI Model Hub documentation